In the modern data-driven world, information moves like water through pipelines—flowing from source systems to analytical platforms where it’s turned into insights. But as data volumes surge and systems become increasingly complex, those pipelines can experience “clogs” and inefficiencies. Optimising ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes is much like maintaining a high-pressure irrigation system: the goal is to ensure continuous, clean, and timely flow.
When done right, optimisation ensures faster data movement, lower costs, and better decision-making for organisations that depend on analytics.
Understanding the Flow of Data
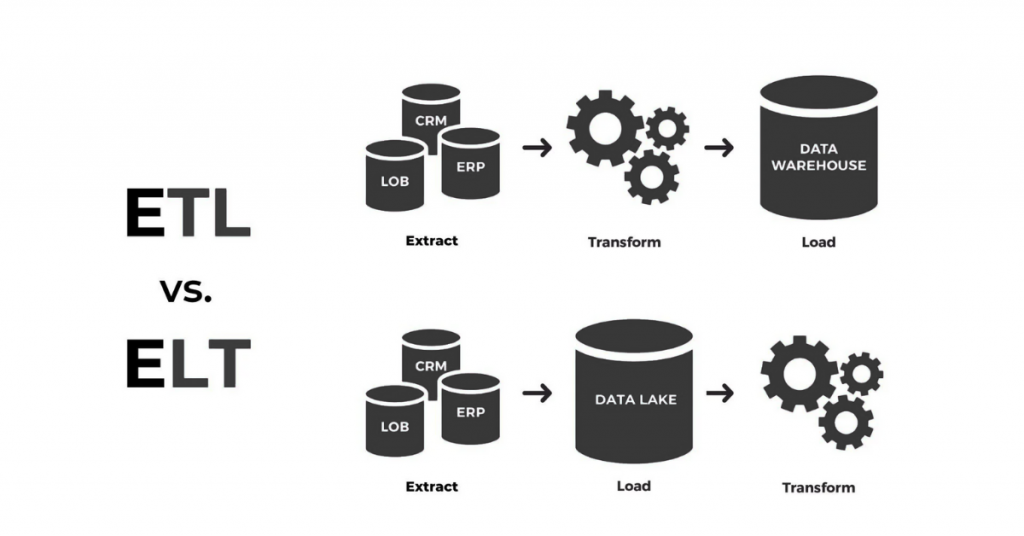
Every ETL or ELT pipeline acts as the circulatory system of a company’s data architecture. The extraction stage pulls data from diverse sources, the transformation stage refines it for analysis, and the loading stage stores it in a data warehouse or lake.
However, performance bottlenecks often appear when datasets are massive or transformations are overly complex. Analysts and engineers must trace these “blockages” and address them through efficient code design, parallelism, and optimal resource utilisation.
Professionals trained through a business analyst course in Pune often start by learning how to visualise this flow—understanding not just the data movement but also the business impact of each delay or inefficiency in the process.
Identifying Bottlenecks in the Pipeline
A critical first step in optimisation is diagnosing where inefficiencies occur. Bottlenecks can appear in several forms: slow network transfers, unindexed database joins, or poorly designed transformation logic.
Think of it as identifying weak links in a chain—if one segment breaks, the entire operation suffers. Advanced monitoring tools like Apache Airflow, Talend, or AWS Glue offer dashboards that highlight slow tasks and failure points.
The key lies in creating a feedback loop. Regular performance audits, coupled with automated alerts, ensure issues are detected before they affect reporting timelines or downstream systems.
Techniques for Performance Tuning
Performance tuning in ETL/ELT pipelines is both an art and a science. It involves fine-tuning configurations, rewriting inefficient queries, and optimising resource allocation.
Batch size adjustments, parallel processing, and in-memory computation can drastically improve speed. Similarly, minimising unnecessary transformations and filtering data early in the pipeline prevents wastage of compute power.
Caching frequently used datasets, using columnar storage formats like Parquet, and leveraging distributed computing frameworks (e.g., Apache Spark) make pipelines more scalable and resilient.
Courses like the business analyst course in Pune often teach learners how to interpret these technical optimisations from a business perspective—understanding how faster, cleaner data directly improves decision-making efficiency.
Scaling for Big Data Environments
When an organisation grows, so does its data volume. Scaling ETL or ELT systems becomes a strategic priority to maintain efficiency without exploding costs.
Cloud-based solutions have revolutionised this area. Tools like Google Dataflow, Azure Data Factory, and Snowflake offer elastic scalability—expanding capacity automatically as workloads increase. But scaling isn’t only about infrastructure; it’s also about intelligent architecture.
Partitioning data, distributing workloads across clusters, and applying asynchronous processing enable pipelines to handle millions of records in near real-time. Scalability ensures continuity even during peak demand, keeping analytics dashboards up to date.
Balancing Cost, Speed, and Reliability
Every data team faces a fundamental trade-off—faster processing usually means higher costs. True optimisation strikes the right balance between speed, reliability, and budget.
Cost-optimisation strategies include using serverless architectures that scale automatically, scheduling non-critical jobs during off-peak hours, and optimising query execution plans.
Data reliability must never be compromised. Proper validation checks, error logging, and data lineage tracking ensure accuracy while maintaining velocity.
When these principles come together, data pipelines not only become efficient but also trustworthy—empowering business leaders to make decisions with confidence.
Conclusion
Optimising ETL and ELT pipelines is about more than just technical tuning—it’s about designing systems that adapt, scale, and deliver value consistently. Like a finely tuned orchestra, every component—from extraction scripts to cloud clusters—must play in harmony to achieve peak performance.
As businesses evolve and data continues to expand, professionals who understand how to streamline these systems will become indispensable. Investing in continuous learning and adopting industry best practices in data transformation will keep organisations ahead of the curve—ensuring their insights flow smoothly, reliably, and at the speed of decision-making.
Leave a Reply